Introduction

All strong AI systems do not begin with a fancy algorithm but with clean, well-prepared data. Before any machine learning model can handle language, raw text needs to be prepared in a systematic way — and that’s exactly where “Text Preprocessing Hacks” become your most powerful weapon. “Text Preprocessing Hacks” are the fundamental abilities that every AI newbie must learn before writing the first line of code to train a model.
From noise removal, punctuation management, word normalisation to irrelevant material removal, Without these strategies, not even the most sophisticated neural networks work. In this article, we’ll cover the most important and practical “Text Preprocessing Hacks” that will instantly take your NLP projects from amateur to professional level, providing your models the clean fuel they need to function magnificently.
Table of Contents
Why Text Preprocessing Hacks Matter in AI

Raw data obtained from the internet, social media or corporate papers is usually always untidy, unreliable and noisy. Text Preprocessing Hacks are the approaches to clean, normalise and structure this raw text before feeding it to any machine learning model. If you don’t use “Text Preprocessing Hacks” the models are forced to learn from noisy and irrelevant signals which reduce the accuracy and generalisation capacity of the models.
It’s like prepping ingredients prior to cooking – no matter how great the chef, lousy ingredients make bad food. The quality of your model’s output is directly proportional to the quality of your preprocessing, making these hacks the single most influential phase in any NLP pipeline across every sector and domain.
The Cost of Skipping Text Preprocessing Hacks
Many newcomers fall into the trap of jumping straight into model training without first applying the right ‘Text Preprocessing Hacks’. The impact is high – models trained on raw text tend to overfit the noise, have difficulty generalising, and make outrageously wrong predictions in production. For example, without the “Text Preprocessing Hacks”, a sentiment analysis model trained on raw social media material would classify “GREAT”, “great” and “Great” as three entirely different words, thus tripling the vocabulary size.
This bloated lexicon is a waste of memory, it slows training, and it confuses the model. Any professional NLP practitioner knows that putting some work into good Text Preprocessing Hacks up front saves a tonne of debugging effort later, and always yields faster training, leaner models, and drastically better real-world performance on all language problems.
Where Text Preprocessing Hacks Fit in the NLP Pipeline
Knowing where “Text Preprocessing Hacks” fit into the larger NLP pipeline is vital for developing efficient and reliable language AI systems. Preprocessing is the first stage and it always occurs before tokenisation, feature extraction, model training and evaluation. “Text Preprocessing Hacks” are the quality control gate that allows only clean, meaningful and regularly structured data to flow into the downstream pipeline.
Modern libraries such as spaCy and Hugging Face ship with out-of-the-box preprocessing utilities but the knowledge of the underlying “Text Preprocessing Hacks” manually allows practitioners to deal with edge circumstances that automated tools may not be able to catch. Whether you are constructing a simple text classifier or a complicated dialogue system, putting “Text Preprocessing Hacks” at the very beginning of your workflow is a non-negotiable best practice that separates experienced NLP engineers from casual experimenters.
Lowercasing and Noise Removal

One of the easiest and most effective “Text Preprocessing Hacks” is to make all the text lower case. This single step makes sure that words like “Python”, “python” and “PYTHON” will be considered as the same tokens by the model. Another fundamental hack in the “Text Preprocessing Hacks” toolset, apart from lowercasing, is removing noise – removing HTML elements, URLs, special characters, digits, and punctuation that have little semantic significance for most NLP applications.
Both strategies significantly reduce the quantity of the vocabulary and increase the consistency of the model. If you are a beginner, you will immediately get cleaner training data and faster convergence while training the model by following these simple ‘Text Preprocessing Hacks’. They are the perfect starting point for anyone who is new to constructing language AI systems from scratch.
Lowercasing as a Core Text Preprocessing Hack
One of the most common “Text Preprocessing Hacks” is to lowercase your text. It’s easy and it has an instant influence on the uniformity of your data. Converting all text to lowercase reduces the model vocabulary greatly and reduces the memory requirements . It also helps the model to recognise the same term in multiple contexts . Lowercasing in Text Preprocessing Hacks is especially important when working on datasets scraped from social media platforms where there is a huge inconsistency in the use of capitalisation – users write in ALL CAPS for emphasis, in Title Case for proper names, and combine styles indiscriminately.
This hack trains the model to attend to semantic meaning rather than superficial formatting variations. > “What Is Natural Language Processing (NLP)? It is precisely the discipline that makes simple yet powerful hacks like lowercasing the foundation of every reliable, production-grade language AI system ever built.” Most NLP frameworks have lowercasing as a one-liner, making it the quickest and most cost-effective Text Preprocessing Hack any beginner can apply right away to his workflow.
Removing Noise with Text Preprocessing Hacks
One of the most important “Text Preprocessing Hacks” is Noise Removal. It is used to improve the signal to noise ratio of the training data before it enters the model. The text data noise may be in the form of HTML tags, URLs, email IDs, special symbols like @, #, %, random numbers, and site scraping artefacts. Text Preprocessing Hacks Noise removal is commonly performed using regular expressions – sophisticated pattern matching techniques that are able to quickly locate and remove undesirable characters from raw text.
For instance, excluding twitter handles and hashtags from a sentiment analysis dataset guarantees that the algorithm learns emotional patterns instead than memorising user identities. Without these “Text Preprocessing Hacks”, models tend to overfit to noise patterns that have zero generalisation value, wasting both computational resources and precious training time that could have been spent on genuinely meaningful language understanding.
Tokenization as a Text Preprocessing Hack

Tokenisation is among the most basic “Text Preprocessing Hacks” of the entire NLP workflow. It’s the process of taking raw text and turning it into small units called tokens, usually words, subwords or characters, that machine learning models can then mathematically manipulate. “Text Preprocessing Hacks” might be as simple as whitespace tokenisation or as complicated as subword tokenisation techniques such as Byte Pair Encoding, employed in state of the art transformer models.
The tokenisation strategy is important, because it will directly affect how the model will see and interpret language. The beginner who learns to master tokenisation as part of his or her “Text Preprocessing Hacks” toolbox is considerably further along in the construction of models that can deal with a broad vocabulary, unusual terms and multilingual text with much more accuracy and robustness.
Word vs Subword Tokenization in Text Preprocessing Hacks
One of the most contested alternatives in “Text Preprocessing Hacks” is between word-level or subword-level tokenisation for your NLP work. Word level tokenisation breaks text into tokens on spaces and punctuation, creating clean legible tokens, but failing with unusual or out-of-vocabulary terms that the model has never seen during training. Subword tokenisation, another clever tool in the “Text Preprocessing Hacks” toolbox, chops words into smaller, meaningful parts, allowing the model to understand new words by putting together known subword pieces.
For example, “preprocessing” might be broken down into “pre”, “process”, and “ing.” This is why contemporary “Text Preprocessing Hacks” prefer subword approaches for production NLP systems that have to deal with the entire diversity and originality of real-world human language (used by BERT and GPT models).
Sentence Tokenization in Text Preprocessing Hacks
Sentence tokenisation is a specialised but no less significant entry in the “Text Preprocessing Hacks” collection, especially for such tasks as document summarisation, machine translation, and dialogue systems. Word tokenisation breaks the text into individual words, sentence tokenisation breaks a document into individual sentences, a procedure that appears straightforward but in fact turns out to be very complicated. In “Text Preprocessing Hacks,” sentence tokenisation has to deal with abbreviations, e.g., “Dr.”, “Mr.”, and “e.g.”, which have periods but do not end the sentence.
They have to deal with quoted speech, bullet points, multi-line formatting that trips up unsophisticated splitting rules. This is why libraries like NLTK and spaCy come with strong sentence tokenisers built-in as part of their “Text Preprocessing Hacks” toolkits. These libraries gracefully handle the above edge cases and ensure that the downstream models receive properly segmented input, preserving the natural flow and meaning of the original document structure.
Stop Word Removal and Stemming Hacks
Stop word removal and stemming are two classic “Text Preprocessing Hacks” that have made their way into the NLP toolkit since the earliest days of information retrieval and search engine development. Stop words are words that appear very frequently in text and have low significance such as “the”, “is”, “at”, “which”, and “on”. They do not add much to the semantic material that models need to learn.
Text preprocessing hacks like removing stop words decrease the size of the dataset and make the model focus on words that really matter. Stemming, which strips words down to their root form (e.g., “running” to “run,” “happily” to “happi”), further consolidates the vocabulary and minimises noise in the feature space before model training commences.
Stop Word Removal in Text Preprocessing Hacks
Stop word removal is one of the most commonly used “Text Preprocessing Hacks” in conventional NLP systems including search engines, document classifiers and topic modelling pipelines. Some words appear in nearly all documents . ” Text Preprocessing Hacks ” such as stop word removal allow the model to focus on terms that truly differentiate one text from another . For instance, in a news article classification job, omitting stop words means the model focuses on words such as “election”, “economy” and “climate” rather than using capacity for words such as “the”, “and” and “is”.
Most of the NLP packages come with pre-defined stop word lists for dozens of languages. This is one of the most accessible “Text Preprocessing Hacks” for novices. However, stop word lists should always be reviewed and customised for the individual area by practitioners, as some common terms have essential value in specialised contexts such as legal or medical text analysis.
Stemming vs Lemmatization in Text Preprocessing Hacks
Stemming and lemmatisation are two closely related but different Text Preprocessing Hacks and knowing the difference is essential for picking the proper method for each NLP work. Stemming is a crude but fast hack that cuts off word endings with rules — “studies” becomes “studi” and “happiness” becomes “happi” — without concern for grammatical correctness. Lemmatisation is one of the more advanced Text Preprocessing Hacks that employs vocabulary and morphological analysis to return the correct base form from the dictionary.
For example, “studies” becomes “study” and “better” becomes “good”. Text Preprocessing Hacks utilising lemmatisation gives cleaner and more linguistically correct outputs but are computationally expensive. If you are building a production system where accuracy is important, then lemmatisation is the Text Preprocessing Hack to apply. If you are prototyping rapidly, or building a large-scale search index, then stemming still has its uses – speed over linguistic precision.
Handling Special Cases with Text Preprocessing Hacks

Standard pipelines have issues with many unusual instances found in real-world text data, and here is where advanced “Text Preprocessing Hacks” really shine. Contractions like “do not”, “can not” and “I am” must be expanded to their full forms. Social media content has slang phrases, emoticons and emojis that require particular handling. Numbers, dates, and currency symbols typically have to be normalised, not removed.
Special situations ( ” Text Preprocessing Hacks ” ) Encoding problems : UTF-8 faults , special characters from non-English languages , unseen whitespace characters that damage tokenisation . The developers that spend the effort to learn these complex “Text Preprocessing Hacks” produce much more robust NLP pipelines that can cope with the full unanticipated diversity of real-world language data at production scale.
Expanding Contractions in Text Preprocessing Hacks
One minor yet super powerful skill in the “Text Preprocessing Hacks” bundle that many novices completely ignore is expanding contractions. Contractions like “won’t”, “they’re”, and “it’s” are really two words combined into one. If you don’t expand them, the model will interpret them as single unknown tokens, rather than the meaningful component words. Contraction expansion: Expand contractions such as “can’t” to “cannot”, “I’ve” to “I have”, and “they’ll” to “they will” before tokenisation.
This can be achieved via lookup dictionaries or rule-based replacement functions. This keeps the model vocabulary clear, consistent and semantically rich. “Text Preprocessing Hacks” Expansion of Contractions This is very useful for Sentiment Analysis and Intent Detection tasks because negation words carry important sentiment reversing meanings which the model must grasp accurately to produce reliable predictions.
Handling Emojis and Slang in Text Preprocessing Hacks
The special challenges of social media NLP call for inventive “Text Preprocessing Hacks” beyond traditional library capabilities. Emojis like 😊, 🔥, and 💯 are rich in emotional content and just removing them loses key sentiment signals in the training data. Advanced “Text Preprocessing Hacks” for emoji handling of converting emojis to their text descriptions – 😊 to “smiling face” and 🔥 to “fire” – keeping their semantic information but in a form that the model can understand.
Similarly, normalisation dictionaries are also used for Internet lingo such as “lol”, “brb”, “tbh”, and “omg” which map informal abbreviations to their standard equivalents. With the increasing number of NLP apps being developed over Twitter, Reddit, Instagram, and TikTok data where emoticons and slang dominate the communication style of billions of active users globally, “Text Preprocessing Hacks” that handle these social media quirks are becoming increasingly crucial.
Vectorization — Turning Text into Numbers

Once the text is cleaned and normalised with “Text Preprocessing Hacks”, the final important step is to turn the text into numerical representations that machine learning models can actually crunch. This is called vectorisation and this is where “Text Preprocessing Hacks” and feature engineering meet. Classical ways are Bag of Words and TF-IDF, whereas newer approaches are dense word embeddings such as Word2Vec, GloVe, and contextual embeddings from transformers.
The quality of upstream Text Preprocessing dictates the quality of these numerical representations – garbage in, rubbish out. > “As powerfully demonstrated in Leverages Large Language Models to Improve NLP Applications, even the most advanced large language models deliver superior results only when they are built on a foundation of meticulously preprocessed and consistently structured text data.” Practitioners learn the full pipeline from cleaning raw text to vectorisation through Text Preprocessing, so they can develop end-to-end NLP systems that work consistently for classification, clustering, translation and generation tasks at any scale.
Bag of Words and TF-IDF in Text Preprocessing Hacks
Bag of Words and TF-IDF are two basic vectorisation techniques at the end of classical “Text Preprocessing Hacks” pipelines and still commonly used today for many practical NLP jobs. Bag of Words turns a page into a vector of word counts – basic, interpretable and fast but ignorant of word order and context. TF-IDF does this by assigning higher weights to words that occur frequently in a document but not so often in the entire corpus . This reduces the weight of the common words and increases the weight of the unique words .
Text Preprocessing such stop word removal, lemmatisation, etc. have a direct and measurable impact on TF-IDF quality. Cleaner input means more meaningful term weights. These Text Preprocessing together with TF-IDF vectorisation still give competitive results for applications like document categorisation, keyword extraction and search ranking without the need of costly deep learning equipment.
Word Embeddings After Text Preprocessing Hacks
The most powerful vectorisation phase after extensive “Text Preprocessing Hacks” is word embeddings, which convert words into dense numerical vectors that capture deep semantic associations. Models like Word2Vec and GloVe learn that “king” minus “man” plus “woman” equals “queen” – a surprising attribute that is completely a consequence of statistical patterns in clean preprocessed text. The quality of these embeddings is very susceptible to the “Text Preprocessing Hacks” we apply upstream – uneven case, noisy characters, unexpanded contractions, all impair embedding quality dramatically.
BERT and GPT are modern transformer based embeddings that go this even farther . They produce context sensitive representations , thus the same word gets different vectors in various phrases . Therefore, Text Preprocessing are vital even in the era of huge language models, because clean consistent input always yields richer, more meaningful, and more transferable numerical representations across every conceivable downstream NLP activity.
Building Your Own Text Preprocessing Pipeline
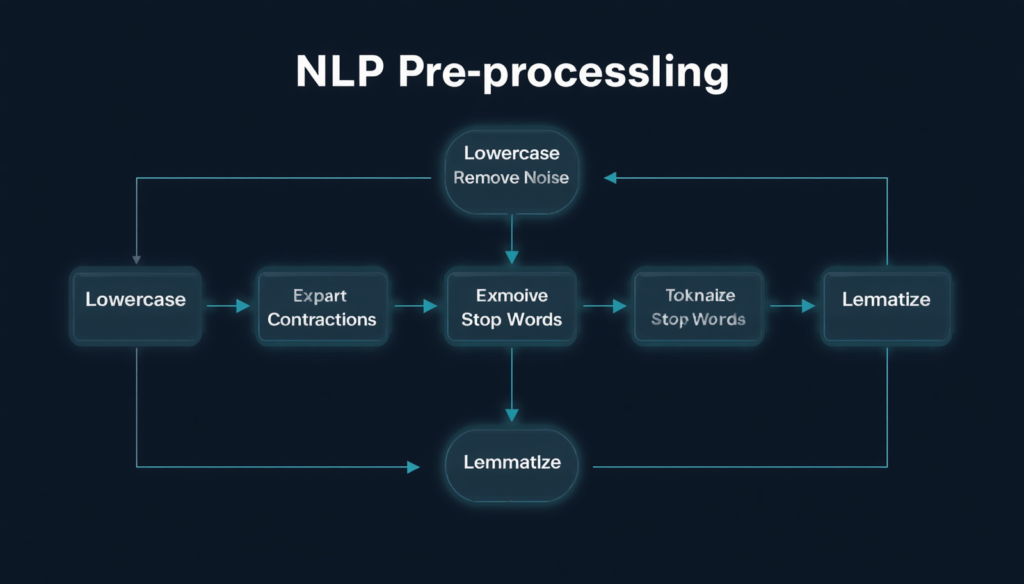
The end goal of learning “Text Preprocessing Hacks” is to build a reusable modular preprocessing pipeline that can be used consistently across all NLP projects. A well constructed pipeline executes each hack in the correct order (lowercasing, noise removal, contraction expansion, tokenisation, stop word removal, lemmatisation, and vectorisation) so that results are reproducible in training, validation, and production contexts.
Text Preprocessing bundled into a pipeline remove manual inconsistencies and speed up experimenting tremendously. Text Preprocessing aren’t just theoretical, but a practical superpower that immediately improves every NLP project you touch. You can build production-level preprocessing pipelines with Python libraries like spaCy, NLTK, and scikit-learn in less than fifty lines of code.
Designing a Reusable Text Preprocessing Hacks Pipeline
One of the best investments any NLP practitioner can make early in their career is to build a reusable pipeline on “Text Preprocessing Hacks”. Each “Text Preprocessing Hack” — lowercasing, noise reduction, tokenisation, stop word removal, lemmatisation — is wrapped into its own clearly stated function that can be toggled on or off based on job requirements in a modular pipeline. The modularity is such that the same pipeline can be used in a sentiment analysis project today and a document summarisation project tomorrow with minimal adjustment.
Pipeline components that implement Text Preprocessing also make debugging easy – if the model starts to lose performance, the practitioner may pinpoint exactly which preprocessing step is the culprit. Whether you use scikit-learn’s Pipeline class or spaCy’s component system, establishing such modular Text Preprocessing pipelines is an elegant, maintainable, and highly scalable engineering strategy that evolves with the complexity of your NLP projects over time.
Testing and Validating Your Text Preprocessing Hacks
Testing and validating every step of your “Text Preprocessing Hacks” pipeline is a vital discipline that differentiates production systems from experimental notebooks. Before deploying any “Text Preprocessing Hack” to a live system, it should be tested against a wide variety of edge circumstances – sentences with emojis, multi-lingual text, very long documents, totally empty strings, etc. We use unit tests for “Text Preprocessing Hacks” to ensure that individual methods work correctly, and integration tests to guarantee the entire pipeline delivers consistent and expected output from start to finish.
Quantitative evidence of preprocessing quality can be obtained by practitioners by measuring vocabulary size, token count distributions and out-of-vocabulary rates before and after implementing Text Preprocessing . Your models will always train on the cleanest, the most reliable data if you start your NLP journey by building this validation discipline around your Text Preprocessing.
People Also Ask
What are the most important Text Preprocessing for NLP beginners?
Begin with lower casing and noise reduction, and then learn Text Preprocessing like as tokenisation, stop word removal, and lemmatisation. These five methods alone will increase the accuracy and speed of training of any NLP model greatly.
Why do Text Preprocessing matter before training an AI model?
Raw text is uneven, untidy. Text Preprocessing help clean, normalise and arrange input so that models learn useful patterns instead of noise resulting in faster training, reduced vocabulary and considerably better real world prediction results.
What is the difference between stemming and lemmatization in Text Preprocessing ?
Text Preprocessing Stemming trims word endings using rules Lemmatisation returns appropriate dictionary base forms Lemmatisation is more accurate for production systems and stemming works well for fast prototyping and big scale search indexing activities.
How do I build a complete Text Preprocessing pipeline in Python?
Chain your Text Preprocessing using SpaCy or NLTK. Lowercase, remove noise, extend contractions, tokenise, remove stop words, lemmatise and vectorise. Wrap each step in a reusable function for clean, modular, production-ready NLP pipeline design.