Introduction
Fine-Tuning LLMs — Imagine you could tap into the brainpower of GPT-4 or LLaMA, but with training tailored to your data, industry lingo, and business needs — that’s the game-changing vision of “Fine-Tuning LLMs.” “Fine-Tuning LLMs” is the effort of customising a powerful pretrained large language model to a certain domain, task or communication style, utilising a carefully curated dataset.
“As powerfully explored in The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs, the journey from understanding basic fine-tuning concepts to achieving genuine production-grade AI breakthroughs is now more accessible, more affordable, and more commercially transformative than at any previous point in the entire history of large language model development.” “Fine-Tuning LLMs” in 2025 is more accessible, more efficient, and more commercially impactful than ever before. Tools like Hugging Face, LoRA, and QLoRA have dramatically lowered the technical and computational barriers to building truly custom AI systems that deliver production-grade results for organisations of all sizes.
Table of Contents
What is Fine-Tuning LLMs?
Fine-Tuning LLMs is the process of further training a large pretrained language model on a smaller, domain-specific dataset to fit its broad capabilities to a specific task or knowledge topic. Unlike training from scratch — which requires billions of dollars of compute and massive datasets — “Fine Tuning LLMs” leverages the rich linguistic knowledge already encoded in the pretrained model, requiring only a fraction of the data and compute to achieve remarkable domain-specific performance improvements. “Fine Tuning LLMs” is what transforms a general-purpose model like LLaMA or Mistral into a specialized medical diagnosis assistance, legal document reviewer, or customer service agent with domain competence.
Why Fine-Tuning LLMs Matters in 2025
“Fine-Tuning LLMs” is now one of the most strategically significant talents any AI-powered firm can build in 2025 — for reasons that go beyond merely boosting model accuracy on domain-specific benchmarks. Pretrained models like GPT-4 and LLaMA are generalists – incredibly capable across the wide variety of activities, but frequently imprecise, inconsistent, or unnecessarily verbose for specialised professional use cases. The article “Fine Tuning LLMs” attempts to bypass these constraints by training models on the exact vocabulary, tone, format, and knowledge patterns of a target domain. Organisations investing in “Fine Tuning LLMs” obtain a sustainable competitive advantage, a proprietary AI capacity that competitors utilising generic APIs cannot imitate or access.
Fine-Tuning LLMs vs Prompting vs RAG
It’s important to understand how “Fine-Tuning LLMs” relates to rapid engineering and Retrieval-Augmented Generation, to enable principled architectural decision making around custom AI systems. Prompt engineering directs the behaviour of a model by feeding it well-formed input instructions without changing the weights of the model – quick and flexible but limited in breadth. RAG augments model answers with retrieved external documents at inference time – great for knowledge currency, but adds latency and complexity. “Fine-Tuning LLMs” permanently encodes domain information and behavioural patterns into model weights, with faster inference, more consistent outputs, and deeper domain expertise than either prompting or RAG that is suitable for highly specialised production applications.
Types of Fine-Tuning LLMs Approaches

In recent years, the landscape of “Fine-Tuning LLMs” has evolved substantially, providing practitioners with a diverse array of strategies that balance off performance, computational expense, data needs, and implementation complexity. “Full fine-tuning” updates all model parameters on the target dataset – maximally expressive but computationally expensive and prone to catastrophic forgetting of pre-trained knowledge. Fine-Tuning LLMs approaches are parameter-efficient and only update a small subset of parameters, which drastically reduces compute and memory needs while keeping most of the general capabilities of the pre-trained model. Instruction fine-tuning, the technique that turned GPT-3 into ChatGPT and changed the landscape of conversational AI applications across the globe, trains models to obey natural language instructions.
Full Fine-Tuning in Fine-Tuning LLMs
Fine-Tuning LLMs Full fine-tuning is the most comprehensive technique. All parameters of the pre-trained model are updated on the target dataset to achieve the highest possible adaptability to the specific domain or job. Full “Fine-Tuning LLMs” provides the best domain adaptation outcomes when adequate compute and data are available, but also comes with certain practical hurdles. You need plenty of high-memory GPUs and it can take days or weeks of training to update billions of parameters. Full “Fine-Tuning LLMs” also suffers from catastrophic forgetting when rigorous training on limited domain data erodes valuable general skills learned during the first pretraining phase on varied text corpora.
Parameter-Efficient Fine-Tuning LLMs
Fast forward to 2025, when parameter-efficient fine-tuning has become the de facto realistic technique to “Fine-Tuning LLMs.” This has radically democratised access to custom AI development, reducing processing needs by orders of magnitude. Methods like LoRA (Low-Rank Adaptation) inject small trainable matrices into the model’s attention layers while leaving all original parameters frozen, and can achieve the same performance as full “Fine-Tuning LLMs” at a fraction of the computational effort.
QLoRA goes a step further by quantising the underlying model to 4-bit precision, enabling “Fine-Tuning LLMs” on consumer-grade GPUs with as little as 24GB of memory. These lightweight methodologies have opened the doors for the building of custom AI models by individual academics, companies and small engineering teams throughout the world.
Data Preparation for Fine-Tuning LLMs
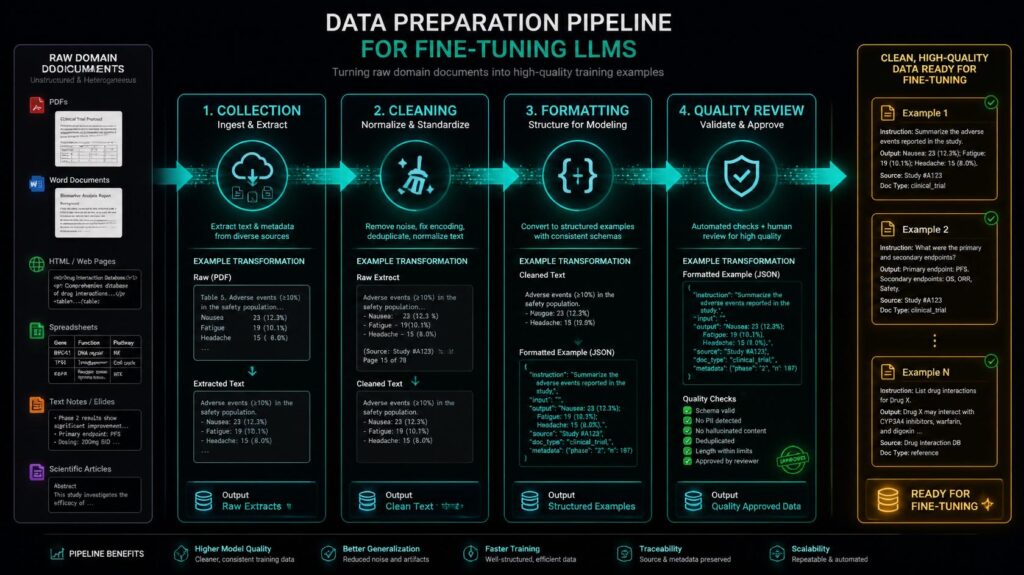
The quality of training data is the most single crucial factor of success in any “Fine-Tuning LLMs” project – a reality best encapsulated by the industry expression “garbage in, garbage out.” Pretraining can afford to be trained on noisy web-scale data due to its enormous bulk . ” Fine Tuning LLMs ” has to work with much smaller curated datasets where each sample has a huge impact on the model’s learnt behaviour . For “Fine Tuning LLMs,” data preparation consists of gathering domain-relevant examples, cleaning and normalising the text, formatting examples into the correct template for the selected fine-tuning objective, and carefully reviewing quality to ensure the model learns accurate and appropriate behaviours for the target production environment.
Dataset Formats for Fine-Tuning LLMs
Choosing the right dataset format is a surprisingly impactful decision in any “Fine-Tuning LLMs” project. The format dictates what the model learns to perform and how it packages its outputs in production. Instruction fine-tuning datasets present each sample as a (instruction, input, output) triplet — training the model to respond to instructions in natural language for different tasks kinds.
Conversational fine-tuning datasets train dialogue behaviour using (human, assistance) message pairings. Datasets for domain adaption “Fine Tuning LLMs” are just lots of domain-specific text to continue pre-training on specialised vocabulary and understanding. One of the most common and expensive mistakes that practitioners make when starting their first bespoke AI project is the poor choice of the dataset format for “Fine Tuning LLMs”.
Data Quality in Fine-Tuning LLMs
In “Fine-Tuning LLMs” projects, data quality perhaps matters more than data quantity. Experienced practitioners report time and again that by carefully curating a small but high-quality dataset they achieve far better downstream job performance than with larger noisy datasets. “Fine Tuning LLMs” data quality indicators: • Correctness and truthfulness • Consistency of tone and style • Absence of damaging or biased content • Length and detail level appropriate for the task • Authentic variety throughout the spectrum of inputs the model will encounter in production Projects on “Fine Tuning LLMs” should spend as much time and effort on data curation and quality evaluation as they do on model training itself — a discipline that separates professional AI engineering from amateur experimentation.
Tools and Frameworks for Fine-Tuning LLMs
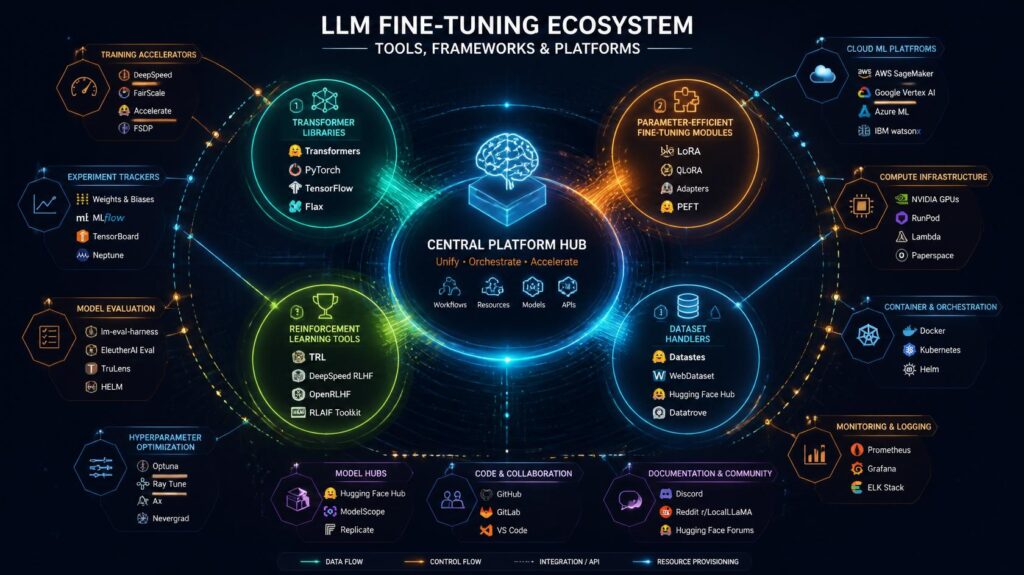
In 2025, the ecosystem of tools and frameworks around “Fine-Tuning LLMs” has grown substantially, making custom AI creation more accessible, reproducible, and production-ready than any prior moment in the history of large language model research. Hugging Face is the one-stop-shop for “Fine Tuning LLMs” tooling — with its Transformers library for model access, PEFT library for parameter-efficient methods, TRL library for instruction and preference fine-tuning, and Datasets library for data administration. Together, these technologies form a complete “Fine Tuning LLMs” ecosystem covering all steps from dataset creation, to model training, to deployment — greatly decreasing the engineering work needed to create production-quality custom AI systems.
Hugging Face for Fine-Tuning LLMs
By 2025, Hugging Face has become the platform of choice for “Fine-Tuning LLMs” and provides a complete and thoroughly defined ecosystem that spans across all the steps of the custom model creation lifecycle from data to deployment. The PEFT package provides clean and consistent APIs for LoRA, QLoRA, prefix tuning and other parameter-efficient “Fine Tuning LLMs” methods that abstract the complexity of changing model topologies. The TRL library offers implementations of Supervised Fine-Tuning, Direct Preference Optimisation and Reinforcement Learning from Human Feedback that allow non-deep RL experts to perform instruction “Fine Tuning LLMs”. With the use of these libraries, Hugging Face has become the primary point of reference for almost every important “Fine-Tuning LLMs” project worldwide.
LoRA and QLoRA for Fine-Tuning LLMs
LoRA and QLoRA have changed the game in “Fine-Tuning LLMs” making bespoke model development practical on the hardware most people and small organisations actually own and operate. LoRA, or low-rank adaptation, is a technique that decomposes the weight update matrices into low-rank products, lowering the amount of trainable parameters from billions to millions while still performing as well as “Fine Tuning LLMs” on most downstream tasks. QLoRA takes it a step further by quantising the frozen base model to 4-bit precision and training LoRA adapters in 16-bit precision. This allows for “Fine Tuning LLMs” of 7B to 70B parameter models on single consumer GPUs . A democratisation of custom AI that was simply inconceivable just two years ago.
Fine-Tuning LLMs in Practice
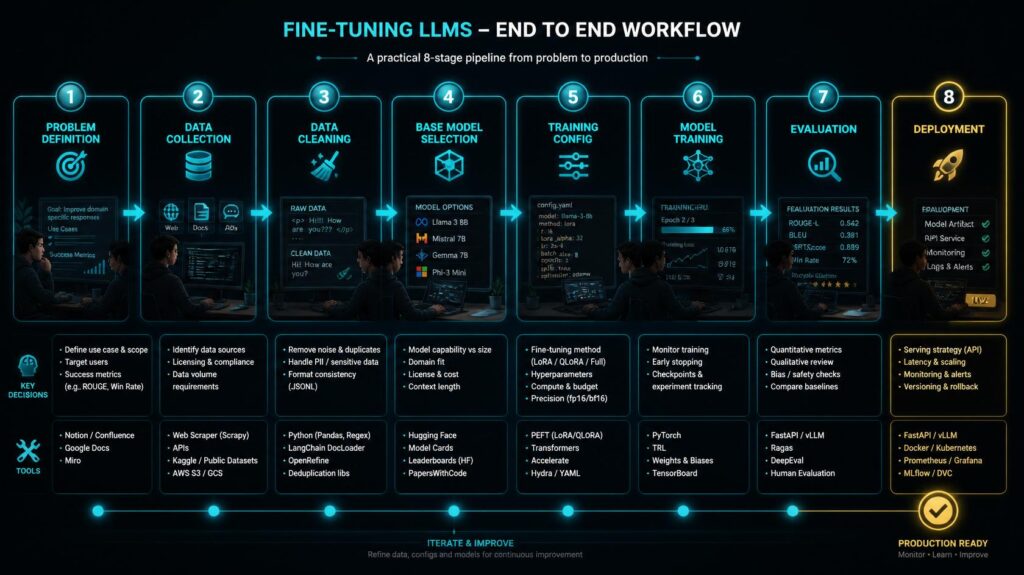
A walkthrough of a genuine “Fine-Tuning LLMs” project, start to finish, to understand the practical concerns, engineering decisions, and typical mistakes that differentiate successful bespoke AI deployments from expensive failures. A typical “Fine Tuning LLMs” approach starts with problem formulation — precisely defining what specific behaviour the fine-tuned model should demonstrate that the base model does not supply sufficiently via prompting.
Then comes dataset collection and preparation, base model selection, training configuration, model training, evaluation and finally deployment. Every step in the “Fine Tuning LLMs” workflow needs to be approached with care and domain expertise – skipping any step inevitably results in models that underperform in production, even though they performed well on held-out assessment criteria during development.
Selecting the Right Base Model for Fine-Tuning LLMs
Selecting a base model is one of the most important early decisions in any “Fine-Tuning LLMs” project, because the base model’s capabilities and limitations set the ceiling for what fine-tuning can accomplish. For “Fine Tuning LLMs”, 7B parameter models like LLaMA-3 7B and Mistral 7B are the sweet spot for capability vs computational accessibility on consumer hardware. 13B to 70B parameter models like LLaMA-3 70B result in significantly better domain adaption results for organisations with enterprise GPU technology. “Fine Tuning LLMs” on instruction-tuned base models (i.e., base models that have already been aligned with human preferences) often gives better results than fine-tuning raw base models as the instruction-following ability provides a solid platform for task-specific adaptation.
Evaluating Fine-Tuning LLMs Results
Rigorous assessment is a discipline that practitioners commonly underinvest in during “Fine-Tuning LLMs” projects, but it is the only reliable way to ensure that fine-tuning has truly improved model performance for the objective task rather than just overfit to the training distribution. assessment methods of “Fine Tuning LLMs” involve automated metrics (perplexity, ROUGE, BLEU, exact match accuracy) and human assessment teams that determine the quality of responses based on criteria such as helpfulness, accuracy, and acceptable tone. “Fine Tuning LLMs” projects should always keep a held-out test set that the model does not view during training, and evaluate on real-world production scenarios that reflect the entire range of inputs that the deployed model will experience.
Challenges in Fine-Tuning LLMs

Despite the impressive advances in equipment and methodology, “Fine-Tuning LLMs” still presents major practical hurdles that every practitioner should be aware of and plan for before embarking on a custom AI development project. Catastrophic forgetting, i.e. degradation of the general capabilities of the pre-trained model when fine-tuned on narrow domain data, is an open problem in “Fine Tuning LLMs” especially when training on tiny datasets for large numbers of epochs. In practice, data collection and annotation are always the most time-consuming and expensive parts of Fine Tuning LLMs projects. “Fine Tuning LLMs” does not solve the hallucination problem (LLMs tend to generate confident but wrong factual statements) and must be managed via evaluation, guardrails, and RAG augmentation in production systems.
Catastrophic Forgetting in Fine-Tuning LLMs
One of the most annoying and common issues in “Fine-Tuning LLMs” is catastrophic forgetting, a phenomena where a model, brilliantly fine-tuned for a given domain, suddenly performs poorly on tasks it did well on before fine-tuning started. This is because aggressive gradient changes during “Fine Tuning LLMs” corrupt the parameter values that encode general knowledge during pretraining. To avoid catastrophic forgetting in “Fine Tuning LLMs”, several techniques are used: training with very low learning rates; training for fewer epochs; using elastic weight consolidation regularisation (Kirkpatrick et al., 2017); mixing domain-specific training examples with general instruction-following examples; and favouring parameter-efficient methods such as LoRA that only modify a small fraction of total model parameters.
Hallucination Management in Fine-Tuning LLMs
A key difficulty that “Fine-Tuning LLMs” can partially resolve but not completely solve for knowledge-intensive production use cases is hallucination, which is the fabrication of confident, fluent, yet factually inaccurate content. Domain-specific “Fine Tuning LLMs” lowers hallucination over the training data themes by strengthening correct factual correlations in the model’s weights. However, fine tuning LLMs on few domain datasets does not prevent the model from hallucinating on topics outside the training distribution.
In production systems for Fine Tuning LLMs, effective hallucination management is achieved using a combination of fine-tuning and RAG for knowledge grounding, output validation layers that check factual claims against trusted sources, and human-in-the-loop review for high-stakes generated content.
Real-World Applications of Fine-Tuning LLMs
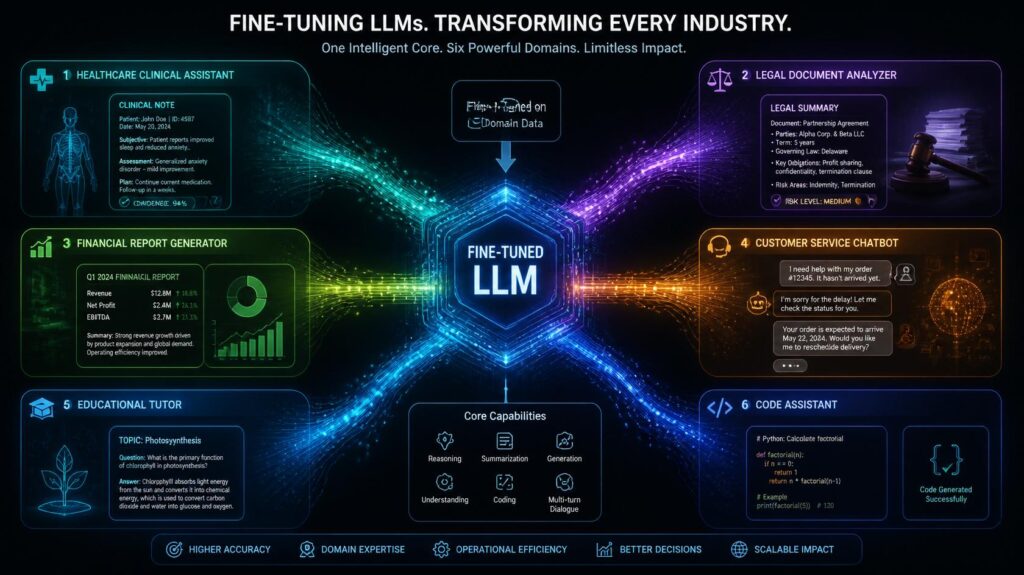
“Fine-Tuning LLMs” already is making a commercial impact across virtually every industry that works with language at scale. Organisations are seeing dramatic gains in task-specific AI performance, quality of user experience, and operational efficiency vs. using generic pretrained models via standard API calls. Healthcare organisations are using “Fine Tuning LLMs” to build clinical documentation assistants that comprehend medical language and produce accurate, properly structured clinical notes from physician dictations. Legal companies use ‘Fine Tuning LLMs’ for contract analysis, for automating due diligence and for legal research support unique to their jurisdiction and practice area. Financial institutions use “Fine Tuning LLMs” for earnings call analysis, regulatory compliance monitoring & personalised investment report preparation.
Fine-Tuning LLMs for Enterprise Applications
In 2025, the most commercially mature and high-value uses of “Fine-Tuning LLMs” are enterprise deployments, where companies are investing heavily in proprietary custom models encoding their institutional knowledge, communication norms, and operational requirements. Customer service organisations utilise “Fine-Tuning LLMs” to build help agents who speak with a brand-consistent voice, grasp product-specific language, and manage company-specific policies with a precision that generic models can’t match.
“As powerfully demonstrated in BERT vs GPT: Which AI Language Model Actually Wins?, choosing the right base model architecture — BERT for understanding-intensive enterprise tasks or GPT for generation-intensive applications — is the single most consequential decision that determines whether a Fine-Tuning LLMs investment delivers transformative business value or disappointing results.” Code-generation and code-review assistants are built by software businesses using “Fine-Tuning LLMs”, trained on the norms of their own codebase, internal APIs, and engineering standards. With each repetition, the proprietary training data builds up, deepening the competitive moat of corporate “Fine-Tuning LLMs” investments.
Fine-Tuning LLMs for Research and Education
Research organisations and educational institutions are learning that “Fine Tuning LLMs” permits the development of domain-specific AI assistants that can significantly expedite knowledge work in forms that generic models do not effectively support. Scientific research organisations utilise “Fine Tuning LLMs” to develop literature review assistants trained on domain-specific paper corpora, models with a level of precision in understanding field-specific technique, citation standards, and technical vocabulary that general models always lack.
“Fine Tuning LLMs” is used by educational institutions to develop personalised tutoring systems that align with specific curricula, pedagogical methods, and student evaluation models. “Fine Tuning LLMs” enables AI systems to learn institutional knowledge directly in the model weights, resulting in systems that are a true reflection of organisational expertise.
Conclusion
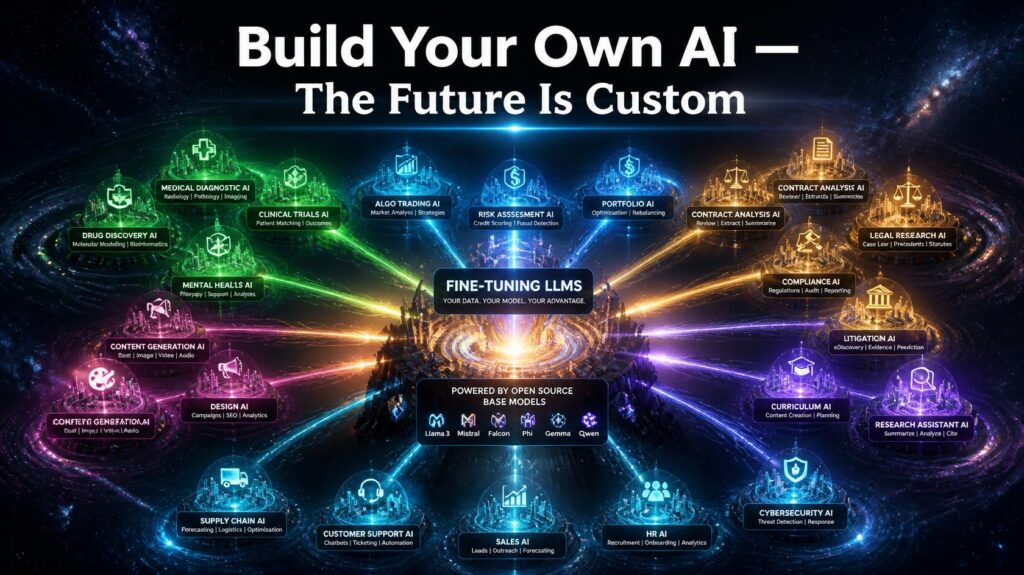
“Fine-Tuning LLMs” has gone from a cutting-edge research approach available only to well-funded AI labs into a practical, accessible, and commercially critical capacity that organisations of all sizes may now use to construct truly tailored AI systems that fulfil their particular needs. The combination of powerful open-source base models such as LLaMA and Mistral, parameter efficient approaches like LoRA and QLoRA, and complete tooling from Hugging Face enabled “Fine Tuning LLMs” more democratised in 2025 than ever before in the history of artificial intelligence. As “Fine Tuning LLMs” matures, the organisations that develop unique bespoke AI capabilities now will have decisive competitive advantages in tomorrow’s AI-powered economy
People Also Ask
What is Fine Tuning LLMs and why does it matter in 2025?
General AI becomes specialised specialists. “Fine Tuning LLMs” adapts sophisticated pretrained models like LLaMA and Mistral to specific domains using small curated datasets, providing production-grade domain expertise that generic API queries and prompt engineering cannot for professional specialised applications.
What is the difference between LoRA and full Fine Tuning LLMs?
Complete fine-tuning updates billions of parameters while LoRA updates millions. “Fine Tuning LLMs” with LoRA makes custom AI development possible on consumer GPUs that most developers and small businesses already own and operate.
How much data do I need for Fine Tuning LLMs on a custom domain?
Quality trumps quantity here. If each example precisely represents the intended task, tone, and knowledge patterns the model must learn for production deployment, “Fine Tuning LLMs” can accomplish excellent domain adaptation with 500 to 1000 high-quality curated examples.
What are the best tools for Fine Tuning LLMs in 2025?
Hugging Face rules the ecology. “Fine Tuning LLMs” in 2025 uses PEFT for LoRA and QLoRA, TRL for instruction tuning and RLHF, Axolotl for reduced training pipelines, and Weights & Biases for experiment tracking to create a full and accessible custom AI development stack.