Introduction

In a world awash with opinions, reviews, tweets and comments, the capacity to interpret human emotion automatically, at scale, has become one of the most economically useful capabilities in all of artificial intelligence. That capacity is “Sentiment Analysis” — the science of teaching machines how to identify, categorise and understand the emotional tone behind human words. Opinion Mining is silently fuelling some of the most impactful AI applications in the current digital economy.
From brand monitoring and customer feedback analysis to political opinion tracking and financial market prediction, Emotion Detection allows machines to detect the mood of human communication with incredible speed and accuracy, whether the text is happy, angry, frustrated or excited. In this blog, we will discuss everything about Opinion Polarity Classification – from basic concepts, key techniques to the most advanced deep learning implementations – giving every AI enthusiast a comprehensive, actionable and insightful understanding of how machines are learning to understand human emotion today.
Table of Contents
What is Sentiment Analysis?
Sentiment Analysis is a subfield of Natural Language Processing that employs computational techniques to detect and extract subjective information — opinions, emotions, attitudes, and sentiments — from textual data. Opinion Mining is also known as opinion mining. It is the process of classifying text as positive, negative or neutral. In more sophisticated applications, it also detects emotions like joy, wrath, fear, surprise, disgust, etc.
Emotion Detection is used in just about every business from retail and hospitality to healthcare and politics. Affective Computing automates the interpretation of human sentiment at huge scale, turning unstructured text data into structured emotional intelligence that corporations, researchers, and policymakers can act upon with speed and confidence that manual analysis could never achieve.
The Core Concept Behind Sentiment Analysis
The core idea of “Sentiment Analysis” is deceptively simple but tremendously powerful in its economic and scientific ramifications. Opinion Mining is about analysing any form of text, be it a product review, a social media post, a customer service transcript or a news item, and then determining whether the general emotional tone of the text is good, negative or neutral.
More complex implementations of Emotion Detection go beyond this three-class classification to detect the intensity of sentiment, the exact aspect of a product or service being evaluated, and the precise emotion being expressed. Affective Computing can analyse millions of text samples per second compared to hours for manual human analysis, making it one of the highest-ROI AI technologies available to organisations of every size functioning in the data-rich digital economy of 2025.
Types of Sentiment Analysis Explained
“Sentiment Analysis” is not a single, monolithic technique, but a rich family of linked approaches, each designed to extract different quantities and types of emotional information from text data. Document-level Opinion Mining classifies the sentiment of the whole document or review. Sentence-level Polarity Detection works on individual sentences, providing a more granular comprehension of mixed-opinion papers. The most advanced version, aspect-based Emotion Detection, pinpoints sentiment towards particular qualities of a product or service, such as “the camera is excellent, but the battery life is terrible.”
Another particular kind of Subjectivity Analysis is emotion detection. It does not only classify sentiments into good and negative, but identifies certain emotional states. The numerous variants of Affective Computing are used for distinct use cases and each variant requires different modelling approaches, data requirements and evaluation methodologies to be reliably deployed in production.
How Sentiment Analysis Works
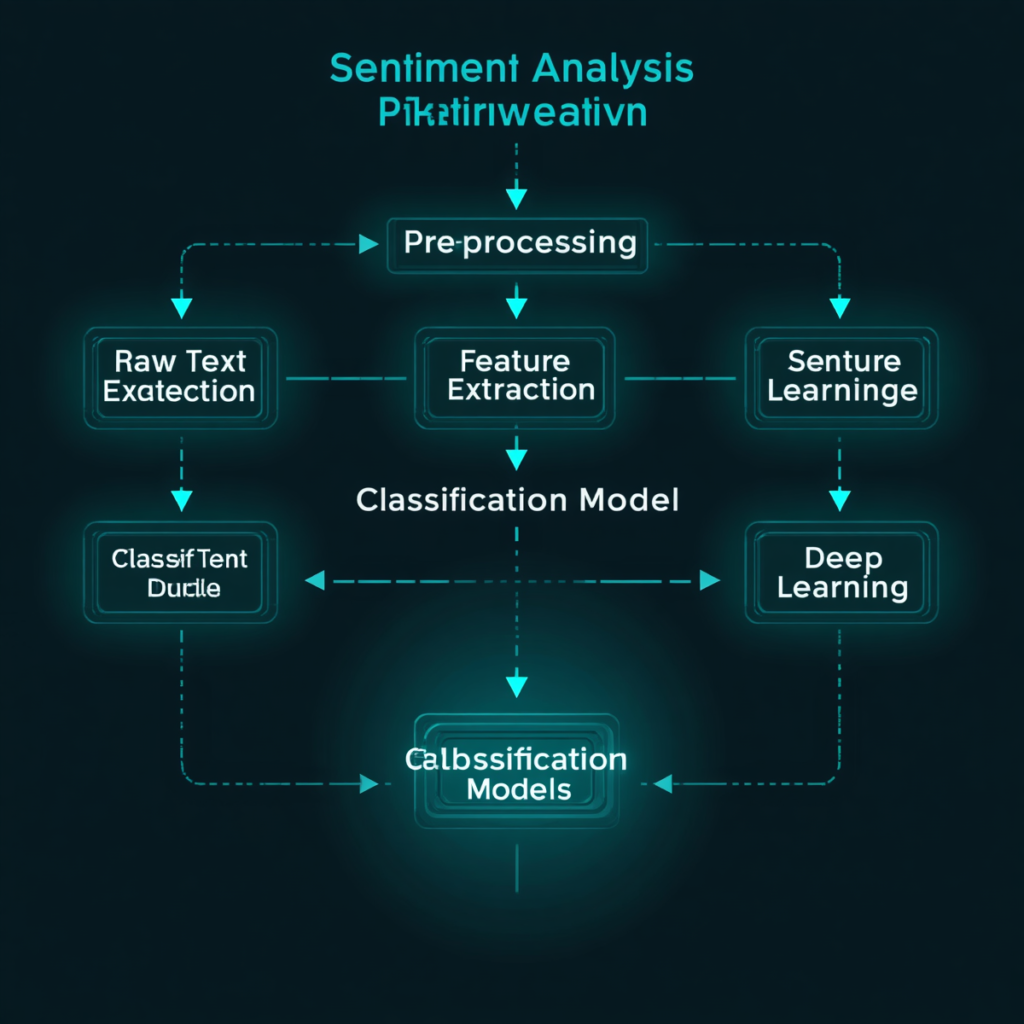
To understand how “Sentiment Analysis” works, one has to look at the computer pipeline that takes raw text and produces emotional classifications. It starts with text pre-processing – cleaning, tokenising and normalising raw input. Characteristics are then extracted from the preprocessed text, either as hand-crafted linguistic characteristics in typical machine learning approaches or as learned representations in deep learning systems.
Then, a classification model maps these features to sentiment labels. Opinion Mining systems can be built on rule-based techniques, traditional machine learning algorithms or state-of-the-art deep learning architectures. Each strategy involves significant trade-offs between interpretability, accuracy, computational cost, and the amount of labelled training data required to reliably function across diverse real-world text domains and languages.
Rule-Based Sentiment Analysis Approaches
The most interpretable and first implementations of “Sentiment Analysis” are rule-based systems that use carefully maintained lexicons and hand-crafted linguistic rules to assign sentiment ratings to text. Rule-based Opinion Mining is based on sentiment lexicons, which are dictionaries that assign positive or negative polarity values to particular words. VADER, SentiWordNet and AFINN are three popular emotion lexicons that assign numerical sentiment scores to thousands of words and phrases.
Rule-based Polarity Detection systems then aggregate these word-level ratings using grammatical rules that take into account negation – “not good” flips the polarity of “good” – and intensifiers – “very good” boosts the score of “good.” Rule-based Emotion Classification is fast, interpretable, and does not require training data, but it is unable to handle sarcasm, domain specific language, and the complex contextual nuances of real-world human communication across many platforms and groups.
Machine Learning for Sentiment Analysis
Machine learning turned “Sentiment Analysis” from a rule-based art to a data-driven science that can reach human-level accuracy on many benchmark datasets. Classical machine learning approaches to Opinion Mining include using algorithms like Naive Bayes, Support Vector Machines and Logistic Regression trained on labelled text datasets where each example is marked with the accurate sentiment label. Emotion Detection feature engineering for machine learning comprises extracting bag-of-words representations, TF-IDF vectors, n-gram features, and hand-crafted sentiment indicators from preprocessed text.
As brilliantly explored in How NLP is Teaching Machines to Understand Human Emotions, this data-driven approach has fundamentally transformed the way machines interpret feelings, moving far beyond rigid rules into genuinely intelligent emotional understanding. The main benefit of machine learning Polarity Detection is that it can learn complicated patterns from data without being explicitly programmed. Affective Computing has been shown to regularly outperform rule based systems on domain specific tasks if enough labelled training data is available. This is especially true when the given domain contains particular language and emotion expressions that generic lexicons are not able to capture well enough.
Deep Learning for Sentiment Analysis

Sentiment Analysis has seen a deep learning revolution, from a task that was heavily dependent on feature engineering, to one where end-to-end neural networks develop rich representations from raw text input. Recurrent Neural Networks, and their variants Long Short-Term Memory networks and Gated Recurrent Units, were the first deep learning architectures to achieve impressive results on Opinion Mining, by processing the text sequentially and remembering the previous words when classifying each new token.
The use of attention mechanisms has further enhanced deep learning Emotion Detection by allowing models to focus on the most emotionally relevant sections of a text while making categorisation judgements. Today, deep learning Polarity Detection with transformer-based models such as BERT has reached an unprecedented degree of accuracy and outperformed all existing algorithms on all major benchmark assessment datasets.
LSTM Networks in Sentiment Analysis
Long Short-Term Memory networks, or LSTMs for short, were the dominant deep learning architecture for “Sentiment Analysis” throughout the mid-2010s, and are still widely used today for many operational applications. This allows Opinion Mining models to learn long-range dependencies — that “not” at the beginning of the sentence affects the sentiment of words much later in the sentence. LSTMs are sequential models, and they read text word by word, maintaining a hidden state, which stores information about the previous words seen.
Bidirectional LSTMs are LSTMs that process simultaneously in both ways, forward and backward. This further improves the accuracy of Emotion Detection as each word may access the context on both sides of the sentence. For production environments with limited resources where deploying transformer models is too computationally expensive, LSTM based Polarity Detection models offer a great compromise between accuracy, inference speed and computational resource requirements, making them practical for real-world applications.
BERT Transforming Sentiment Analysis
With BERT we are able to provide contextual word representations that capture the complete complexity of emotional language with remarkable precision and nuance, radically and irrevocably changing the field of ‘Sentiment Analysis’. Trained on massive text corpora, then fine-tuned on labelled sentiment datasets, BERT-based Opinion Mining models consistently deliver state-of-the-art performance on a variety of domains — product reviews, social media posts, news articles, clinical notes — without any task-specific feature engineering.
BERT’s bidirectional attention enables Emotion Detection models to take the entire sentence context into account when assessing the emotional meaning of each word, neatly handling negation, sarcasm, and complex multi-clause sentences that stump simpler models. Domain-specific BERT versions like FinBERT for financial Polarity Detection, BioBERT for clinical text, and TweetBERT for social media push performance even further by adjusting pre-trained representations to specialised emotional vocabulary and communication styles.
Aspect-Based Sentiment Analysis

The most fine-grained and economically valuable level of sentiment analysis is aspect-based “Sentiment Analysis”. It assigns a favourable or negative emotion and also detects the sentiment about particular characteristics or attributes of a product, service or entity being discussed. Traditional document-level Opinion Mining misses out on all these nuances, i.e. a restaurant review can be positive overall but bad in waiting time, positive in food quality and ambience.
Aspect-based Emotion Detection turns this complicated mixed-opinion text into structured sentiment tuples – (aspect, sentiment) pairs – providing businesses with actionable knowledge of precisely what parts of their offers please or disappoint clients. This level of granularity of Polarity Detection is far more commercially beneficial than global polarity scores to steer focused product enhancements and customer experience optimisation.
Identifying Aspects in Sentiment Analysis
The first important step in aspect based “Sentiment Analysis” is to determine accurately which feature of a product or service is discussed in each sentence or clause of the review text. Approaches to aspect identification vary from simple keyword matching with pre-defined aspect dictionaries to sophisticated neural models learning from context to detect aspects. Aspect-based Opinion Mining pipelines often use named entity identification and dependency parsing to extract aspect terms and their related opinion expressions from complex grammatical structures.
For example, in the sentence “The screen resolution is stunning but the keyboard feels cheap”, Emotion Detection must find “screen resolution” and “keyboard” as aspects, and relate “stunning” to the former and “cheap” to the latter — a difficult task that requires real linguistic understanding, not just simple keyword matching or superficial text pattern recognition.
Real-World Applications of Aspect-Based Sentiment Analysis
One of the most ubiquitous NLP technologies in the world is Aspect-based “Sentiment Analysis”, powering customer intelligence solutions for thousands of companies in every consumer-facing sector. e-commerce giants like Amazon and Alibaba use aspect-based Opinion Mining to automatically summarise user evaluations by product feature – battery life, display quality, build quality, value for money — to provide buyers with structured purchase choice support. Hotel firms and restaurant organisations are using Mood Detection to track guest input on TripAdvisor, Yelp and Google Reviews to find certain service areas that require immediate operational improvement.
To identify emerging quality issues before they trigger expensive recalls, automotive manufacturers are using aspect-based Emotion Detection to analyse warranty claim statements and social media conversations. The business intelligence value that can be derived from granular, aspect-based Polarity Detection always justifies significant corporate effort in setting up and maintaining these complicated NLP systems.
Sentiment Analysis Across Different Domains

One of the most important practical facts of “Sentiment Analysis” is that the representation of sentiment differs dramatically between domains, sectors, and communication mediums, making domain adaptation an important engineering task. For example, the phrase “unpredictable” may have a negative connotation in a product evaluation but a favourable one in a movie review discussing an exciting plot twist.
Opinion Mining algorithms that are trained on Amazon product evaluations generally don’t fare well on financial news or clinical patient comments unless they are adapted to the domain. Understanding these domain-specific sentiment patterns and investing in domain-adapted Affective Computing models is critical for companies looking to extract reliable, production-grade emotional intelligence from their text data across the full diversity of sources and communication styles their business generates on a daily basis.
Social Media Sentiment Analysis
The most complex, but also the most beneficial field for “Sentiment Analysis” is social media. It features specific linguistic qualities in the form of abbreviations, slang, emoticons, hashtags, sarcasm, code-switching . These features are in constant flux, and do not conform to the usual NLP assumptions on text preparation. Opinion Social media platforms like Twitter, Reddit, Instagram and TikTok generate billions of text samples full of emotion every day Mining a goldmine of real-time public opinion intelligence for firms, governments and academics.
Specialised social media Emotion Detection models have to take into account emojis as bearers of emotion – 😊 strongly positive, 😡 strongly negative – and decode online jargon which ordinary sentiment lexicons cannot decipher at all. Live social media Mood Detection delivers brand monitoring dashboards that will alert marketing teams to sudden spikes in unfavourable sentiment so they can react quickly to a crisis before it spirals out of hand and damages the company’s reputation in the always-on digital attention economy.
Financial Sentiment Analysis
Sentiment Analysis is one of the most economically valuable NLP applications in the entire financial services business since financial markets are heavily influenced by human sentiment. Financial Opinion Mining systems gather market sentiment cues from news stories, earnings call transcripts, analyst reports, SEC filings, and social media discussions that forecast price movements, volatility, and investor behaviour.
General-purpose models routinely mistake domain-specific phrases such as “bearish”, “write-down”, “revenue miss” and “guidance cut”, which contain strong and precise sentiment signals in financial text corpora on which specialised financial Polarity Detection models such as FinBERT are pre-trained. Hedge funds and quantitative trading firms pour significant resources into proprietary Emotion Classification systems that analyse thousands of news sources in real time to extract actionable sentiment signals that fuel algorithmic trading strategies that produce measurable alpha in competitive and information-rich financial markets.
Challenges in Sentiment Analysis

Despite great advances in deep learning, “Sentiment Analysis” still suffers from significant, and often fundamental, challenges that affect its reliability in real-world deployments. Sarcasm and irony – “Oh great, another Monday” – mean the opposite of what they say and are a constant source of deceit for models, which can only read the surface mood of words without any awareness of their pragmatic sense. A fundamental difficulty for Multilingual Opinion Mining is the shortage of data for low-resource languages, where there isn’t enough labelled training data to develop effective models.
Cultural context plays a vital role in the manifestation of sentiment. The intensity Americans display on social media is different from the Japanese norm of communicating. Even the greatest Emotion Detection algorithms have problems with negation. These challenges remind the practitioners that although there are impressive breakthroughs, the development of fully powerful and universally dependable Affective Computing systems is still an open and extremely challenging research field that requires further innovation.
Sarcasm Detection in Sentiment Analysis
Sarcasm is probably the most notorious adversary of automated “Sentiment Analysis,” and a basic problem that even the most complex transformer models can’t reliably solve. When somebody writes “I just love waiting 45 minutes for my food”, every word has pleasant surface-level sentiment but the real emotional content is very negative. The detection of sarcasm in Opinion Mining does not only need comprehending the words but also the context: the medium, the author’s style of communication, and occasionally the entire conversation history.
As comprehensively explored in Word Embeddings & Vectors: The Hidden Language of AI, the rich semantic representations that modern embedding models produce are precisely what enable AI systems to move beyond surface-level word sentiment toward the deeper contextual understanding that sarcasm detection demands. Multimodal Affective Computing methods that leverage tone of voice, facial expressions and contextual metadata with text offer promising results for sarcasm identification in video and audio content. Training Emotion Detection models on datasets annotated for sarcasm and irony has also resulted in measurable improvements. However, perfect sarcasm detection is still elusive and is one of the most fascinating open problems in the field of computational pragmatics and affective computing research today.
Multilingual Challenges in Sentiment Analysis
Global marketplaces mean customer input is arriving in dozens of languages simultaneously and this presents a profound scalability challenge for businesses engaged in Multilingual “Sentiment Analysis” Creating a unique, excellent Opinion To build mining models for all languages in reality would need huge labelled datasets and computing power that most organisations can’t afford. Multilingual transformer models such as mBERT and XLM-RoBERTa are trained on texts in more than 100 languages at the same time and are able to conduct cross-lingual Emotion Detection, translating the knowledge of emotion learnt in high-resource languages to low-resource languages with little additional tagged input.
Zero-shot cross-lingual Polarity Detection – applying a model trained just on English sentiment data directly to Spanish or Arabic text — works remarkably well with multilingual transformer models, substantially decreasing the data collection load for worldwide Mood Detection deployments. But there are cultural differences in how individuals express sentiment, so having at least some examples tagged in the target language is still a great assistance for true, accurate Affective Computing.
The Future of Sentiment Analysis

There are numerous converging technology trends shaping the future of “Sentiment Analysis” that will make emotional AI understanding substantially more accurate, sophisticated and universally applicable than anything accessible today. Research labs are already developing systems for multimodal Opinion Mining covering text, voice tone, facial expressions, and physiological signals simultaneously. For customer-focused organisations, real-time Mood Detection incorporated in customer service platforms, smart devices and social media monitoring tools is becoming the operational norm.
Another frontier of transformation is emotion-aware AI assistants that change their communication style to the recognised sentiment of the user. As huge language models become more complex, Affective Computing will transform from being a separate classification task into something that is an embedded part of general AI systems that can truly empathise and generate emotionally intelligent responses.
Multimodal Sentiment Analysis
The most exciting and revolutionary research trend in emotional computing is the multimodal “Sentiment Analysis”, i.e. overcoming the limits of text-only systems, and evaluating sentiment in numerous simultaneous input channels. In a spoken customer care engagement, the spoken words carry only part of the emotional signal – tone of voice, pace of speech, pitch variation and pauses might tell more about customer anger or contentment than the words. Multi-modal Opinion Mining systems integrate texts, audio features, and, if available, facial expression data to produce deeper and more accurate sentiment assessments than what can be gathered from any single modality.
CMU-MOSI and CMU-MOSEI are benchmark datasets that evaluate the performance of multimodal Emotion Detection on text, audio and video together. The commercial use of multi-modal Affective Computing for call center analytics, video review analytics and real-time customer interaction monitoring is an early stage multi-billion dollar market potential under development and deployment.
Emotion-Aware AI Powered by Sentiment Analysis
The ultimate objective for “Sentiment Analysis” is not only to detect emotion, but to enable AI systems to respond to it with true emotional intelligence and empathy. Real-time Emotion Detection based emotion-aware AI assistants may detect frustration from the user and immediately adjust their communication style – slowing down, simplifying language and delivering more comfort. In customer service, AI systems with Opinion Mining capability can escalate to a human agent the moment a negative sentiment crosses a threshold, stopping the erosion of client connections emotionally before it is too late.
Affective Computing is used to study mental health applications such as early detection of sadness, anxiety and suicide ideation from text and voice patterns, potentially saving lives through timely intervention. As Mood Detection becomes more accurate, more multimodal, and more deeply embedded into AI systems at every touchpoint of human-machine interaction, machines will progress closer and closer to the elusive goal of real emotional understanding that mimics authentic human empathy and social intelligence.
People Also Ask
What is Sentiment Analysis and how does it work in AI?
It makes computers get the feeling of text. “Sentiment Analysis” employs NLP and machine learning to automatically determine the sentiment of text as positive, negative or neutral, powering brand monitoring, customer feedback and financial market intelligence systems around the world.
What is the difference between rule-based and deep learning Sentiment Analysis?
Rules rely on lexicons while deep learning relies on data. At production scale, “Sentiment Analysis” using BERT and LSTMs considerably outperforms rule-based systems on complicated text, handling negation, sarcasm and domain-specific language with far greater accuracy and dependability.
How is Sentiment Analysis used in financial markets?
It reads market sentiment in real time. Sentiment Analysis analyses news, earnings calls and social media to find bullish or bearish signals. These are used by algorithmic trading systems to make data-driven investment decisions with incredible speed and a measurable competitive advantage.
What are the biggest challenges facing Sentiment Analysis today?
The trickiest difficulties include Sarcasm, cultural context and multi-lingual data. “Sentiment Analysis” still suffers with irony and low-resource languages, but multimodal models that combine text, voice and facial expressions are quickly decreasing these performance gaps with impressive results.