Introduction

In 2017, a tiny team of researchers at Google published a paper called “Attention Is All You Need” — and nothing in artificial intelligence was ever the same again. That seminal research presented Transformers & Attention, an architectural breakthrough that replaced the sequential processing constraints of older neural networks with a powerful parallel attention mechanism. “Transformers & Attention” meant machines could comprehend the relationship between words across entire publications all at once, instead of word-by-word. Today, all major AI language systems, GPT-4, BERT, Claude, Gemini, are based on “Transformers & Attention”. Making it the single most important architectural breakthrough in the history of modern artificial intelligence and natural language processing.
Table of Contents
What Are Transformers & Attention?
“Transformers & Attention” is, at its core, a radically new approach to handling sequential data – especially human language – that solves the key limitations of all previous neural network architectures. Recurrent networks read the text word by word, one after the other. “As brilliantly explained in Transformer Attention Mechanism in NLP, the revolutionary shift from sequential recurrence to parallel global attention is precisely what gave machines the ability to understand entire sentences simultaneously — unlocking language intelligence at a scale and speed that no previous architecture could even remotely approach.
“ Transformers & Attention take all the words at once and use mathematical attention scores to decide how much each word should influence the interpretation of each of the other words in the sentence. This ability to process in parallel makes “Transformers & Attention” orders of magnitude faster to train and more capable of capturing long-range language connections than any architecture ever encountered in the history of deep learning.
The Problem Transformers & Attention Solved
Before “Transformers & Attention” the primary architectures used for NLP were Recurrent Neural Networks and their derivatives – LSTMs and GRUs. The models read the text one step at a time and kept a hidden state that conveyed information across the sequence. This sequential processing led to two severe problems: disappearing gradients which impeded learning of long-range relationships and inability to parallelise training across GPUs .
“Transformers and Attention” killed two birds with one stone by abandoning sequential recurrence in favour of a global attention mechanism that directly relates every word to every other word. This allows both parallel computation and perfect long-range dependency capture regardless of the distance between related words in the input sequence.
The Core Intuition Behind Transformers & Attention
The fundamental idea of “Transformers & Attention” is elegantly simple: when you understand a word in a sentence, some other words are more important than others. In the sentence ‘The animal didn’t cross the street because it was too tired’, you have to pay much, much more attention to ‘animal’ than you have to pay attention to’street’ in order to know what ‘it’ refers to. Transformers & Attention do this mathematically by taking a weighted total of all the word representations . The weights ( the attention scores ) tell us how relevant each word is to the current word being processed . “Transformers & Attention” is an elegant approach that resolves coreference, captures syntax and understands semantics within a single unified computational framework.
The Self-Attention Mechanism in Transformers & Attention
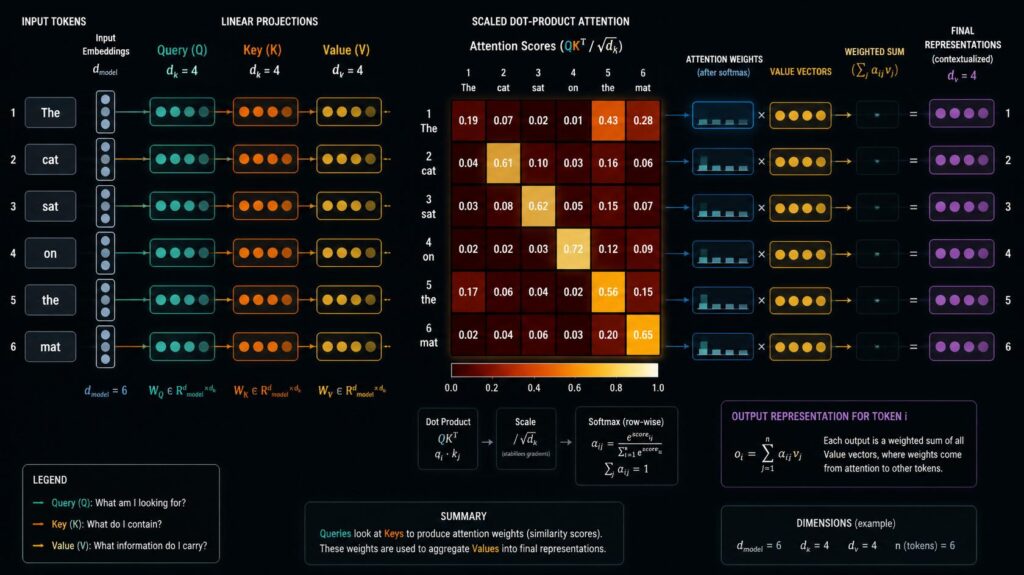
The self-attention mechanism is the mathematical heart of ‘Transformers & Attention’ — the unique computational procedure that allows each word to dynamically attend to all other words in the input sequence when generating its contextual representation. Self-attention projects each input token into three vector spaces, namely Query, Key and Value, via trainable linear projections. The attention score of any two tokens is calculated as the dot product between their Query and Key vectors normalised and scaled by a softmax function. The normalised scores are used to weight the Value vectors to obtain the final contextual representation. “Transformers and Attention” is based on this technique and produces complex, context-sensitive representations of words that capture meaning with remarkable precision and nuance.
Query, Key and Value in Transformers & Attention
The core of “Transformers & Attention” is the Query, Key and Value framework, which is a lovely analogy taken from the idea of database retrieval systems. The Query is what a token is looking for – the information it requires from other tokens to understand itself in context. The Key is what each token provides, a description of its contents that other tokens can verify. The Value is the real information that each token adds when picked by attention.
“Transformers and Attention” compute attention scores by matching Queries against Keys and utilise these scores to obtain weighted combinations of Values, creating contextual representations that encode both local syntax and global semantic links across the whole input sequence.
Scaled Dot-Product Attention in Transformers & Attention
“Transformers & Attention” uses something called Scaled dot-product attention to calculate the attention score for all token pairings concurrently. The raw attention score between token i and token j is the dot product of their Query and Key vectors, scaled by the square root of the Key dimension. This scaling factor prevents dot products from becoming too large in high dimensional spaces, which would cause softmax to produce vanishingly small gradients.
“Transformers and Attention” Then softmax is used over all scores of each Query to get normalised attention weights summing to one. This elegant formulation enables us to compute “Transformers and Attention” efficiently as a single matrix multiplication. This makes the entire attention operation extremely parallelizable over modern GPU technology, and allows for training on enormous text corpora at unprecedented speed and scale.
Multi-Head Attention in Transformers & Attention
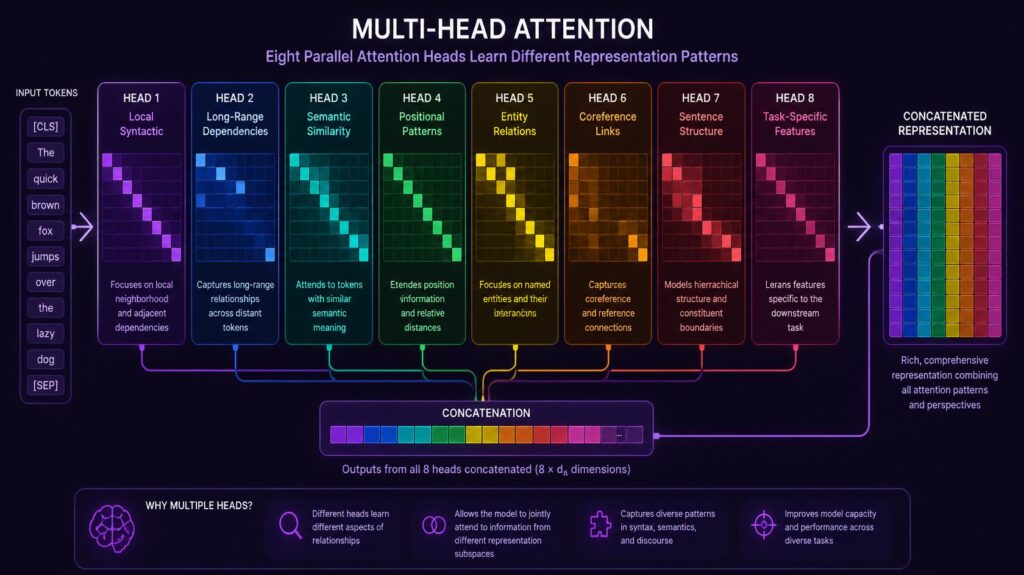
One of the biggest novelties in “Transformers & Attention” is the concept of multi-head attention. That is, you do several self-attention operations in parallel, each with its own learnt Query, Key and Value projection matrices. Each attention head in Transformers & Attention learns to attend to different types of relationships in the input – one head might learn to attend to syntactic dependencies, another to coreference resolution, another to semantic similarity.
All the attention heads are concatenated and projected using a final linear layer to generate a rich multi-perspective picture for each token. In “Transformers & Attention” multi-head attention always outperforms single-head counterparts. Language is multi-relational and you need to be aware of syntax, semantics and discourse structure simultaneously.
How Multiple Heads Enhance Transformers & Attention
In “Transformers & Attention”, the authors explain the power of many attention heads, which can represent simultaneously different language occurrences that a single attention head cannot model well. Studies visualising the attention patterns learned by individual heads in “Transformers & Attention” models have shown intriguing specialisation — some heads consistently track subject-verb agreement across long distances, some follow pronoun reference chains, and some align semantically related words regardless of their syntactic relationship.
“Transformers & Attention” do this rich, multi-perspective comprehension without any explicit supervision about what linguistic phenomena each head should learn – the specialisation is totally from the end-to-end training objective on raw text data at vast scale.
Attention Visualization in Transformers & Attention
Visualising attention patterns has been one of the most common techniques to analyse and understand what Transformers & Attention models learn during training. Tools for visualising attention such as BertViz depict the attention weights between each pair of tokens as arcs of varying colour, indicating which words each token focuses on most strongly in the process of creating its contextual representation.
Attention visualization-based researchers exploring “Transformers and Attention” have found that different levels learn qualitatively distinct patterns – lower layers prefer to acquire local syntactic patterns while higher layers collect abstract semantic correlations. Attention visualisation offers valuable insights into “Transformers and Attention” . However, researchers have cautioned that attention weights do not always accurately represent the causal importance of each token for the model’s final prediction. Thus, additional interpretability methods are needed for a complete interpretation of the model.
The Complete Transformer Architecture in Transformers & Attention
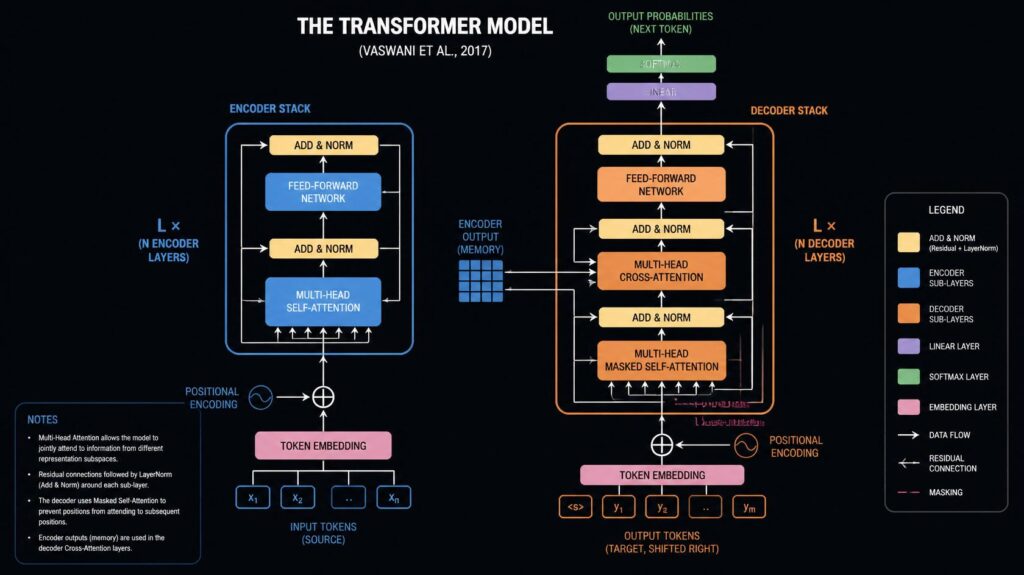
The full architecture of “Transformers & Attention” is split into two parts — encoder that transforms input text into contextual representations and decoder that generates output text from these representations. In “Transformers and Attention”, each encoder layer is a multi-head self-attention sublayer followed by a position-wise feed-forward network. Residual connections and layer normalisation are used surrounding each sublayer. The decoder is quite similar, but has a cross-attention sublayer that attends to the encoder output.
This means that the decoder in “Transformers and Attention” can employ information from the input when creating each output token. This encoder-decoder architecture made “Transformers and Attention” the canonical architecture for sequence-to-sequence tasks such as machine translation, text summarisation, and question answering.
Positional Encoding in Transformers & Attention
Since “Transformers & Attention” look at all the tokens at once, not one after the other, they don’t inherently have any idea of word order, but word order is very vital for meaning in human language. Positional encoding is the elegant approach “Transformers and Attention” employ to introduce sequence position information into token representations. The original “Transformers and Attention” work used sinusoidal positional encodings , which are fixed mathematical functions of position, and provide a unique encoding vector for each location in the sequence.
These positional vectors are simply added to the token embeddings prior to being fed into the first attention layer. Recent variants of “Transformers and Attention” such as RoPE and ALiBi use learnt or relative positional encodings, which generalise better to greater sequence lengths than the ones used during training.
Feed-Forward Networks in Transformers & Attention
Same with the other token representations of the layer after the attention sublayer . For each layer of the encoder and decoder of “ Transformers & Attention ” , a position-wise feed-forward network is applied to every token representation . The feed-forward part of “Transformers and Attention” is two linear transformations with a ReLU or GELU activation in between, often scaling up the representation to four times the model dimension in the hidden layer before projecting back down to the original dimension. So attention learns correlations between tokens .
In the section on ” Transformers and Attention ” they describe the feed-forward network that operates on each token representation in isolation . This allows the model to do complicated non-linear transformations on the output of the attention . The feed-forward layers in “Transformers and Attention” have been proven to operate as key-value memory stores. They encode factual knowledge that the model obtains during inference to answer factual queries and provide replies informed by that knowledge.
Pre-Training and Fine-Tuning with Transformers & Attention
The most impactful paradigm has been enabled by “Transformers & Attention”: pre-training on enormous text corpora, then fine-tuning on specific downstream tasks – a two-stage strategy that has democratised access to sophisticated NLP skills across every domain and sector. “Transformers and Attention” models are trained to acquire rich general-purpose language representations from billions of tokens of web text, books and code without any task-specific supervision during pre-training.
“As comprehensively explored in Named Entity Recognition: How AI Spots Names, Places & Dates, the fine-tuning of pre-trained Transformers & Attention models is the precise mechanism that transforms general language intelligence into highly specialized production-grade NLP systems capable of spotting names, places and dates with remarkable accuracy and reliability.” Fine-tuning: The pre-trained “Transformers and Attention” model is customised to a specific task — sentiment categorisation, named entity recognition, question answering — with a limited amount of labelled task-specific data. This pre-train and fine-tune methodology profoundly revolutionised the economics of NLP, bringing state-of-the-art performance within reach of organisations without large computational resources.
Bidirectional Transformers & Attention
BERT (Bidirectional Encoder Representations from Transformers) is one of the most impactful applications of “Transformers & Attention”. It shows how much better bidirectional pre-training is than unidirectional pre-training for tasks involving language interpretation. BERT pre-trains “Transformers and Attention” with two objectives: Masked Language Modelling with some tokens “masked” and then predicted from context on both sides at the same time, and Next Sentence Prediction.
BERT’s “Transformers and Attention” are bidirectional, so during pre-training each token attends to all other tokens in both directions, leading to deeply contextual representations that transfer powerfully to eleven diverse NLP tasks simultaneously—breaking new state-of-the-art records across named entity recognition, question answering, sentiment analysis, and textual entailment when BERT was initially published in 2018.
GPT — Generative Transformers & Attention
The autoregressive analogue to BERT in the “Transformers & Attention” ecosystem is GPT — Generative Pre-trained Transformer — which uses a decoder-only architecture pre-trained on next-token prediction to provide amazing text generating capabilities. BERT’s Transformers and Attention are optimised for comprehension. GPT’s “Transformers and Attention” are optimised for production — to produce fluent, coherent, and factually grounded writing by learning to predict each next token (word) given all preceding tokens in the sequence.
The family of GPT models, from GPT-1 to GPT-4, has demonstrated impressive scaling properties; models utilising the “Transformers and Attention” architecture have improved across virtually all language benchmarks as model size, training data, and compute resources grow, leading to the discovery of emergent capabilities that appear suddenly at certain scales and were not anticipated by previous work.
Variants and Evolution of Transformers & Attention
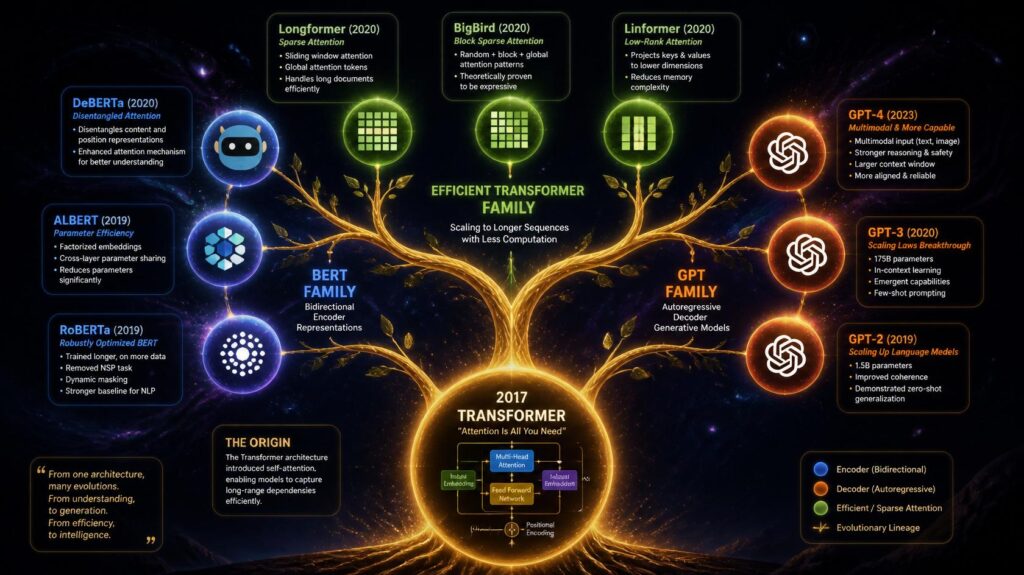
Since the initial 2017 publication, the “Transformers & Attention” architecture has produced an astonishing ecosystem of variants, each tackling specific limits of the original design or extending its capabilities to new modalities and jobs. Efficient variations of “Transformers & Attention” — Longformer, BigBird, Linformer — solve the quadratic computational complexity of standard attention, which makes processing very long documents prohibitively expensive.
In sparse “Transformers & Attention” the computational cost is reduced by using structured sparsity patterns, while much of the modelling power is preserved. Cross-lingual “Transformers & Attention” models such as mBERT and XLM-RoBERTa scale the architecture to process more than 100 languages simultaneously, while domain-specific “Transformers & Attention” variants such as SciBERT, LegalBERT, and FinBERT fine-tune pre-trained representations to specialised professional vocabularies and linguistic patterns.
Efficient Transformers & Attention for Long Documents
The typical “Transformers & Attention” have an inherent computing bottleneck — the self-attention operation is quadratic in the sequence length, making it unfeasible to analyse documents of more than a few thousand tokens on standard hardware. This constraint is tackled by various approximation mechanisms in efficient forms of “Transformers and Attention”. Longformer enables “Transformers and Attention” to handle documents up to 16,000 tokens quickly by combining local windowed attention with global attention to unique tokens.
BigBird combines local, global and random attention patterns. The Linformer approximates the whole attention matrix using a low-rank factorisation. These efficient “Transformers and Attention” variations have permitted the analysis of whole legal contracts, scientific papers, and book chapters – greatly expanding the practical applicability of the architecture to real-world long-document NLP applications.
Multimodal Transformers & Attention
The “Transformers & Attention” design has been astonishingly adaptive beyond text, organically expanding to graphics, audio and video through inventive tokenisation of non-text inputs. Transformers and Attention are applied to images by splitting them into fixed-size patches, flattening each patch into a vector, then passing the series of patch vectors through typical transformer layers.
DALL-E, Stable Diffusion and GPT-4V use multimodal “Transformers and Attention” that jointly model text and image tokens in a common representation space. Audio “Transformers and Attention” models such as Whisper leverage mel-spectrogram patches to achieve state-of-the-art voice recognition across 99 languages. The universality of “Transformers and Attention” across modalities is making convergence towards unified foundation models that understand and generate all human communication channels simultaneously.
Real-World Impact of Transformers & Attention
In practice, the impact of ‘Transformers & Attention’ goes far beyond academic benchmarks, into essentially every corner where language and intellect collide in the modern economy. Search engines based on Transformers and Attention are semantically more relevant than their keyword-matching predecessors (e.g., Google’s BERT-powered search, Bing’s GPT-4-powered search). “Transformers and Attention” is used by healthcare providers to mine insights from clinical notes, link patients to trials, and accelerate drug discovery.
Transformers and Attention are being used by legal tech companies for contract evaluation and due diligence. Financial institutions use Transformers and Attention in sentiment analysis, fraud detection and monitoring compliance with regulation. “Transformers and Attention” are so widely applicable across industries that they may be the most economically revolutionary AI technology introduced in the last decade.
Transformers & Attention in Healthcare and Science
“Transformers & Attention” are becoming transformative tools in healthcare and scientific research, where the ability to process and interpret massive amounts of specialised text at superhuman speed gives real-world benefit of profound magnitude. DeepMind’s AlphaFold utilises “Transformers and Attention” to solve a 50-year-old grand challenge in biology: predicting protein structure from sequencing . It models correlations between amino acid locations in whole sequences.
Transformers and Attention in the Clinic: Extracting Diagnoses, Medications & Treatment Outcomes from Electronic Health Records with Clinician-Level Accuracy In drug discovery pipelines, “Transformers and Attention” are used to explore scientific literature for molecular interaction patterns, which can accelerate the discovery of candidate compounds from years to weeks and potentially save countless lives through speedier development of life-saving medicines.
Transformers & Attention Powering Generative AI
The most evident result of “Transformers & Attention” is the generative AI revolution — the surge of AI systems able to generate human-quality language, code, graphics, and audio that has taken the world by storm since 2022. Hundreds of millions of people use generative AI products like Copilot, Gemini, Claude, and ChatGTP every day, all of which are based on ‘Transformers and Attention’ architectures, trained on a vast scale.
These powerful contextual representations, produced by “Transformers and Attention,” are the basis for the ability of these systems to follow instructions, help with coding, write creatively, and reason about hard topics. The economic and social effects of generative AI powered by “Transformers and Attention” are still taking shape, but initial indications point to it as potentially one of the most important technological shifts in the history of human civilisation.
Conclusion

“Transformers & Attention” is the most dramatic and profound architectural shift in the history of artificial intelligence, going from a 2017 research paper to the foundation of every major AI system on the globe. “Transformers and Attention” was not just a step forward, but a paradigm shift in how machines process and understand language, breaking free from sequential constraints with elegant parallel attention that scales seamlessly from sentence-level NLP to multimodal reasoning across broad knowledge domains.
Transformers and Attention continue to evolve with more efficient architectures, richer multimodal capabilities, and deeper integration into every aspect of human digital life. Their foundational role in the AI-powered future of humanity is ever more profound, indispensable, and truly world-changing in every sense of the word.
People Also Ask
What are Transformers and Attention and why did they shock the AI world?
Parallel intelligence superseded sequential processing. In 2017, “Transformers and Attention” introduced a global attention mechanism that connects every word, allowing GPT-4, BERT, and Claude to understand language faster, deeper, and more accurately.
How does the self-attention mechanism work in Transformers and Attention?
Words check each other for relevancy. “Transformers and Attention” create Query, Key, and Value projections for each token, scaled dot-product attention ratings between all pairs, and weighted contextual representations that encapsulate local syntax and global semantic links.
What is the difference between BERT and GPT in Transformers and Attention?
GPT generates, BERT understands. BERT’s “Transformers and Attention” employ bidirectional encoding for language understanding, whereas GPT uses autoregressive decoder-only architecture for text production. Both are built on the same innovative attention basis but optimised for different NLP capabilities.
How are Transformers and Attention being used in healthcare and science?
They boost medication discovery and clinical intelligence. “Transformers and Attention” power AlphaFold’s protein structure predictions, clinical record diagnoses, and biomedical literature molecular pattern mining, reducing years of research to weeks and saving lives.